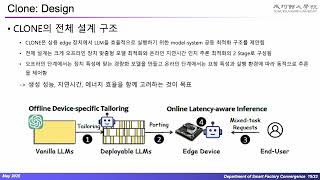
Media Summary: Presenter: Dong-Woo Kim - Department of Smart Factory Convergence 1. Title: CLONE: Customizing LLMs for Efficient Latency ... Optimus: Accelerating Large-Scale Multi-Modal Joint Keynote Address: Accelerating Software Development: The
Usenix Atc 25 Clone Customizing Llms For Efficient Latency Aware Inference At The Edge - Detailed Analysis & Overview
Presenter: Dong-Woo Kim - Department of Smart Factory Convergence 1. Title: CLONE: Customizing LLMs for Efficient Latency ... Optimus: Accelerating Large-Scale Multi-Modal Joint Keynote Address: Accelerating Software Development: The Resource Multiplexing in Tuning and Serving Large Language Models Yongjun He and Haofeng Yang, ETH Zurich; Yao Lu, ... Multi-agent AI systems are becoming essential for multi-step production applications, but require specialized models that are ... In this video, you will see a practical example of Agentic AI using a compound workflow of multiple large language models (