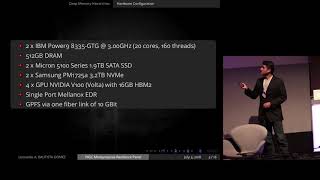
Media Summary: Fault tolerance is becoming increasingly important since the probability of permanent hardware failures increases with machine ... In this video from PASC18, Leonardo Bautista from the Barcelona Supercomputing Center presents: Easy and Efficient Jophin John, Technical University of Munich; Michael Gerndt, Technical University of Munich The estimate that the mean time ...
Towards Optimal Multi Level Checkpointing 0717 - Detailed Analysis & Overview
Fault tolerance is becoming increasingly important since the probability of permanent hardware failures increases with machine ... In this video from PASC18, Leonardo Bautista from the Barcelona Supercomputing Center presents: Easy and Efficient Jophin John, Technical University of Munich; Michael Gerndt, Technical University of Munich The estimate that the mean time ... At the Virtual HPC User Forum Special Event, Dr. Gene Cooperman explains why Checpoint-Restarts are needed, the ... TRY THIS YOURSELF: Flink relies on snapshots of the state it is managing for both ... Learn how to find real performance bottlenecks in production using OpenTelemetry, flame graphs, metrics, and execution profiling ...
The recent entrance of the High-Performance Computing (HPC) world into the exascale era challenges how vast amounts of data ...