Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: One Click Templates Repo (free): Advanced Inference Repo (Paid Lifetime ...
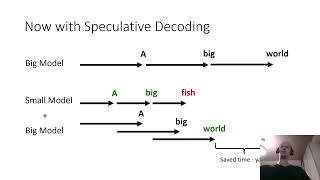
Speculative Decoding Explained - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: One Click Templates Repo (free): Advanced Inference Repo (Paid Lifetime ... Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...