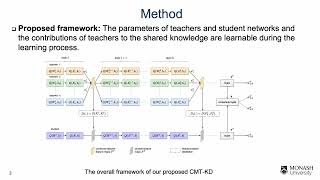
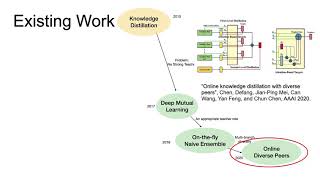
Media Summary: Support the channel❤️ A clear and comprehensive explanation of Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Hossein Mobahi, Google Research In supervised learning we often seek a model which minimizes (to epsilon optimality) a loss ...
Knowledge Distillation In Deep Neural Network - Detailed Analysis & Overview
Support the channel❤️ A clear and comprehensive explanation of Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Hossein Mobahi, Google Research In supervised learning we often seek a model which minimizes (to epsilon optimality) a loss ... Authors: Zhenzhu Zheng (University of Delaware)*; Xi Peng (University of Delaware) Description: We present Self-Guidance, ... Here I try to explain the basic idea behind 230623 Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning