Media Summary: Running AI inference directly on client machines reduces latency, improves privacy by keeping all data on the client, and saves ... FOLLOW ME: INSTA: Twitter: LinkedIn: ... The New Stack team went to KubeCon, and among a host of important topics, we learned about
It S Webassembly But In Webgpu - Detailed Analysis & Overview
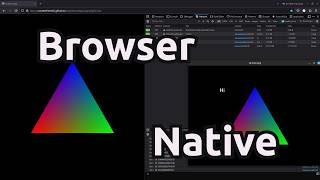
Running AI inference directly on client machines reduces latency, improves privacy by keeping all data on the client, and saves ... FOLLOW ME: INSTA: Twitter: LinkedIn: ... The New Stack team went to KubeCon, and among a host of important topics, we learned about Get the FREE browser AI project from the video: ⚡ Become a high-earning AI engineer: ... Last stream we dug into WGPU. Can we use it with a shader to ship WASM utilizing Source: 0:00 Intro & survey 1:26 Taca focus 2:52 Shader translation 4:01 Zig demo app ...











![[Quick Demo #05] NervLand Terrain rendering tech demo in web browser with WASM + WebGPU](https://i.ytimg.com/vi/tNAO56sxuBQ/mqdefault.jpg)
